| Name | Last modified | Size | Description | |
|---|---|---|---|---|
| Parent Directory | - | |||
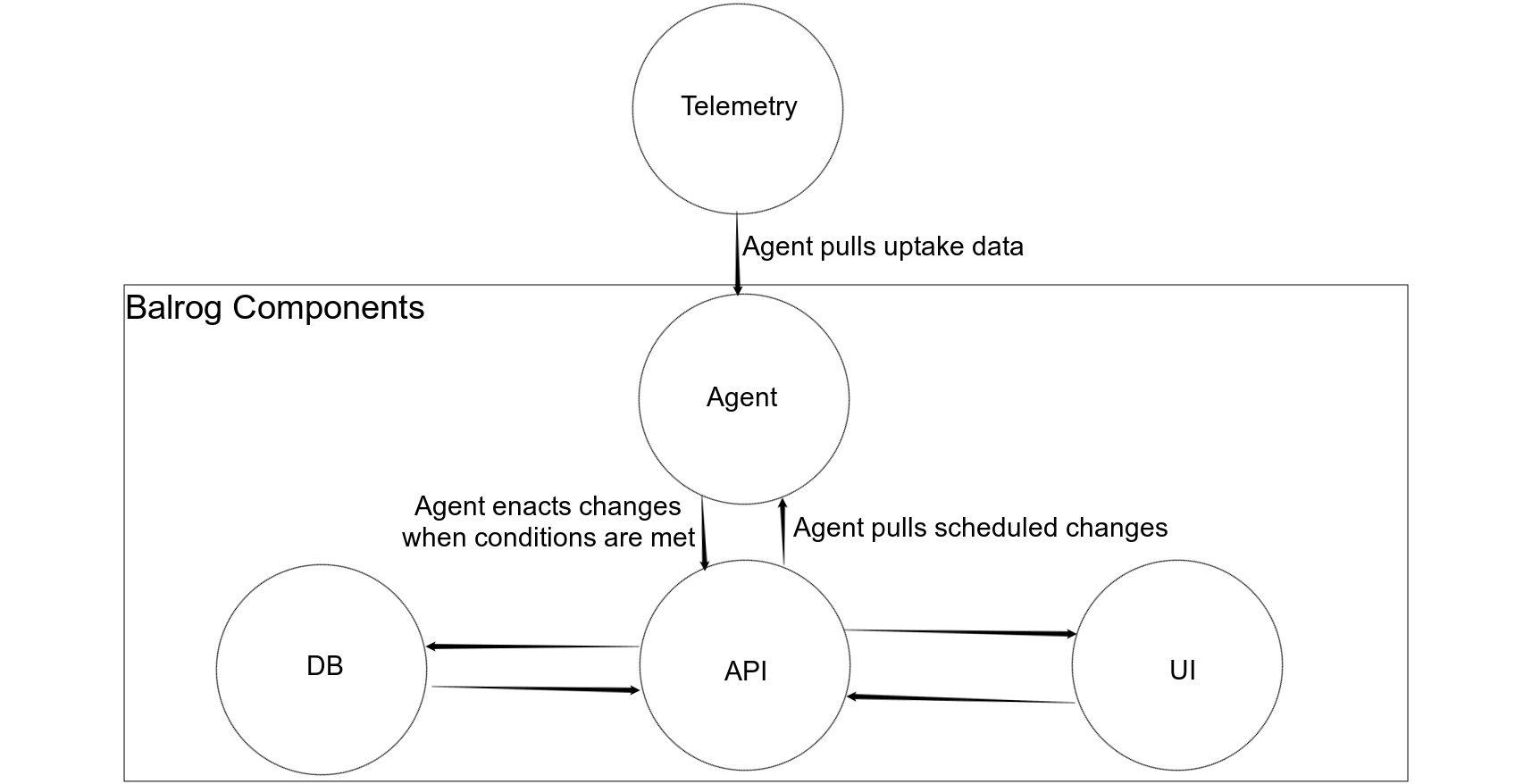
| balrog-agent.png | 2024-07-28 22:16 | 82K | ||
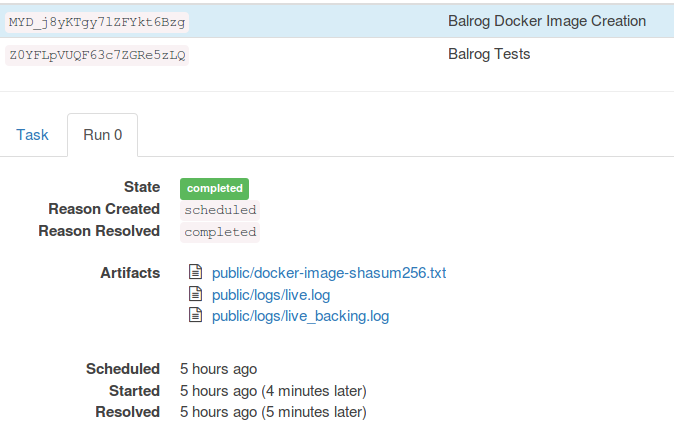
| balrog-dockerbuild.png | 2024-07-28 22:16 | 40K | ||
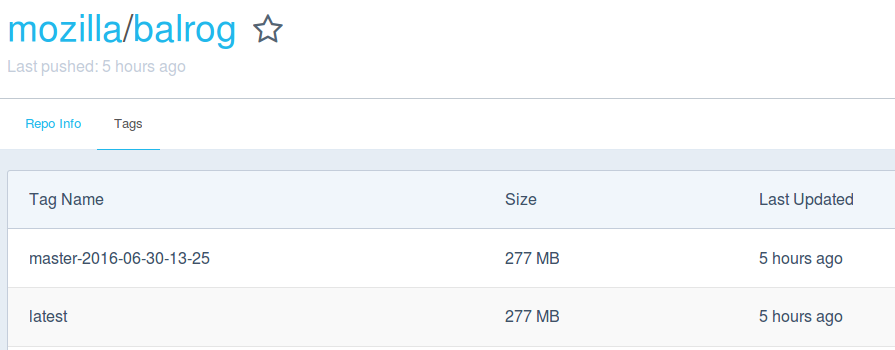
| balrog-dockerhub.png | 2024-07-28 22:16 | 22K | ||
| balrog-firefox.jpg | 2024-07-28 22:16 | 5.8M | ||
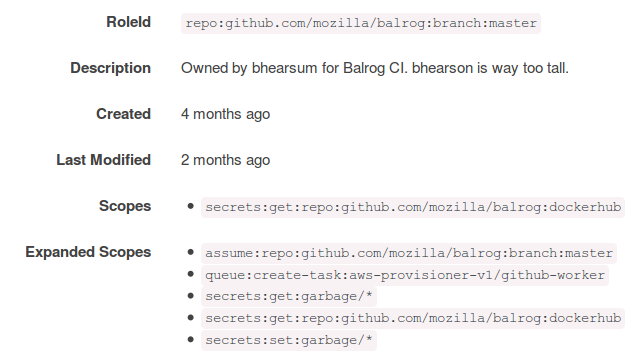
| balrog-role.png | 2024-07-28 22:16 | 35K | ||
| balrog-rules-ui.png | 2024-07-28 22:16 | 44K | ||
| balrog-splash.png | 2024-07-28 22:16 | 219K | ||
| bugzilla-midair.png | 2024-07-28 22:16 | 53K | ||
| dockerhub-secret.png | 2024-07-28 22:16 | 14K | ||
| mso-bugs.png | 2024-07-28 22:16 | 332K | ||
| release-automation-graph.png | 2024-07-28 22:16 | 661K | ||
| scheduled-changes-ui.png | 2024-07-28 22:16 | 45K | ||
| ship-it.png | 2024-07-28 22:16 | 102K | ||
| system-addon-updates.png | 2024-07-28 22:16 | 20K | ||
| wp-content/ | 2015-07-12 10:03 | - | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}