Balrog in 2016 & 2017
This past year has been a big and exciting one for Balrog. We made the transition to Docker, migrated to new infrastructure, participated in Google's Summer of Code for the first time, bootstrapped System Addon updates, and much, much more. In total, 129 tickets were closed, with a significant portion of those being done by volunteers. I'd like to highlight a few things in particular.
Toolchain Improvements
Early on in the year I spent a good deal of time modernizing Balrog's toolchain. I upgraded most of the Python packages, switched to Tox, added Taskcluster for CI, and started using Docker for local development and testing. All of these things combined made it dead-simple to run Balrog on your laptop. This helps with reproducing bugs and testing new work, but the most important aspect ended up being how easy it made it for new developers to get to work. Without this change I wouldn't have felt comfortable proposing Balrog work for Summer of Code, and I highly doubt we would've had many (if any) volunteers working on it.
Looking back on this, I'm now firmly of the belief that if you have some extra time, spending it on things that reduce developer friction is one of the best things you can do. For new projects, make sure you build in time for this at the start.
Volunteers are Awesome
Speaking of volunteers, we've got some awesome ones, and that's pretty much a first for Release Engineering. We've always had a tough time opening up our work to volunteers, primarily because our systems are often difficult to hack on locally. All the work I just talked about to reduce developer friction made this a non-issue for Balrog, and opened the door to start advertising good first bugs, and applying for Summer of Code. I was so amazed and impressed with how many people came knocking when it was made much easier to get started.
But as I look back, I've also realized that there's another part to it: spending the time. When I submitted a Summer of Code proposal, I knew I would have to spend some time mentoring, and it helped put me in the right mindset when volunteers started coming along. While some will just send a PR with a great patch out of the blue, others need a bit more guidance to get started. This doesn't mean that the latter group are less skilled or less valuable, so you shouldn't ignore them. In fact, one of the most active contributors to Balrog is someone that started out in this group. If you can find the time to help these people learn and grow, it can pay dividends down the road.
I want to send out a special thanks to a few of our volunteers in particular. Varun Joshi, our Summer of Code student, who improved the efficiency of our l10n update submissions, and did much of the initial work on System Addons. Njira Perci, who has done the vast majority of the UI work in the past year (I'm pretty sure she's our resident expert on it now!). And Ninad Bhat, who did all of the other work on System Addons, and is now helping out a lot with Multiple Signoff. Without you three I don't know what we would've done!
Transition to Cloud Operations
Early in the year we made the decision to move the production infrastructure of Balrog to CloudOps' platform. While there was a lot of small details to figure out, this went extremely well, and I want to thank the Web Operations, Database Operations, and Cloud Operations teams for making it so smooth. Because it's AWS and Docker based, we now have much more control over the production stack, and are able to scale much more easily as we add more load to Balrog.
System Addon Updates
One of the things I'm most proud of this year is how quickly we were able to spin up updates for System Addons. In the past this may have been a huge headache, but because of Balrog's flexible design we were able to get them working quite quickly, and make some improvements later. Ninad in particular spent considerable time making improvements to that process.
Multifile Updates
Since we began shipping them, Balrog has served updates to Gecko Media Plugins. And since we added a second one, they've been a huge headache for us to manage. After Varun implemented multifile updates, shipping new versions of these plugins became trivial.
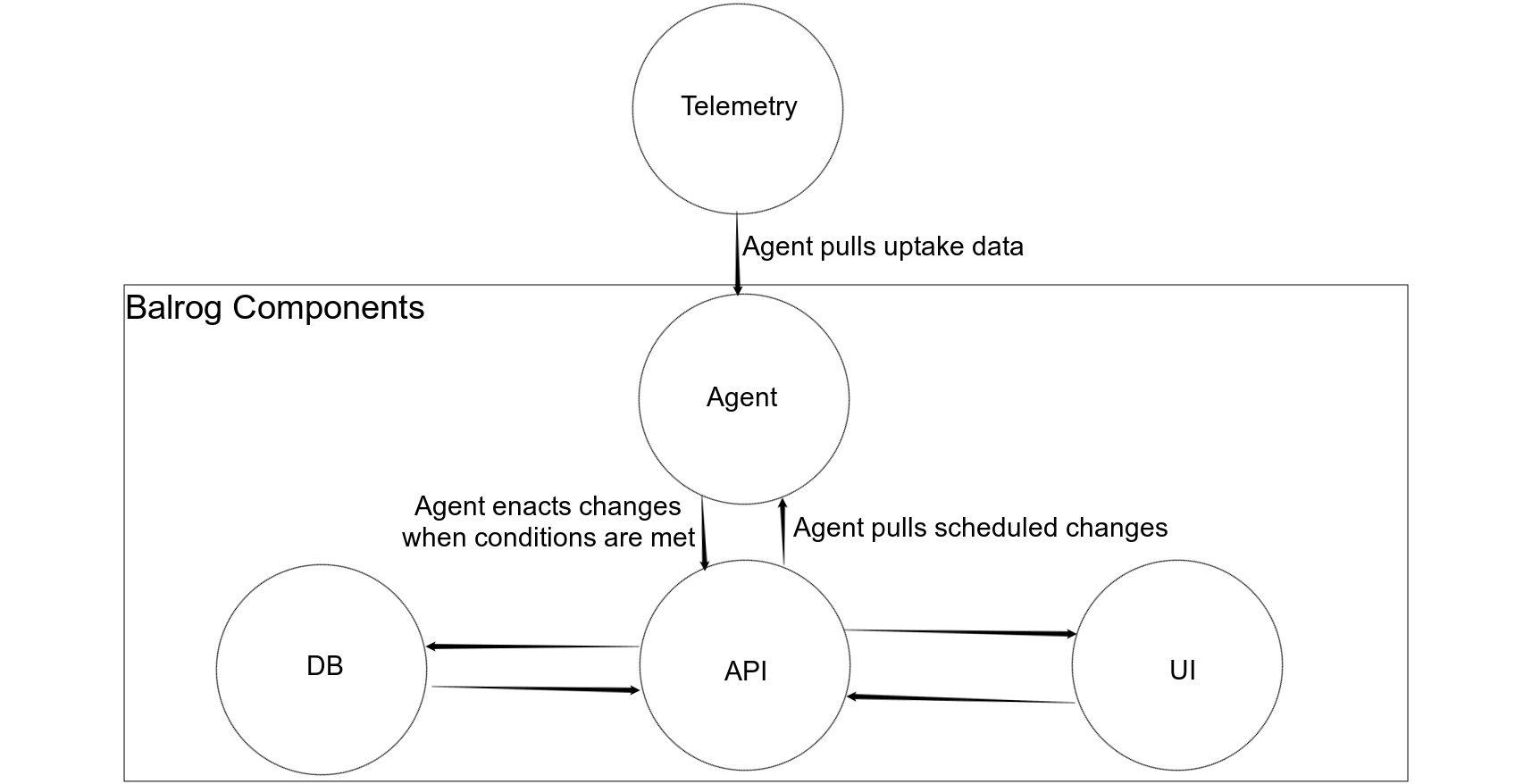
Scheduled Changes
Code-wise, this was my biggest accomplishment of the year. The Scheduled Changes work allows us queue changes to be enacted at a later time, and once we have lower latency ADI information, release uptake. Once the latter is available, we'll be able to do much better throttled rollouts rather than the guesswork we currently do. This system has also become the basis for the Multiple Signoff work we started in Q4.
2017
This past year has been a great one for Balrog, but I expect 2017 to be even better. Here's some of the things we're looking at for 2017:
- Finishing up the work on Multiple Signoffs, which will make Balrog much more resilient to bad actors or credential theft.
- Digging into unifying update requests that Firefox makes. Laura talked a lot about this at Mozloha, and I think we can greatly improve uptake of a lot of different things that Firefox queries for.
- Authentication improvements. I'd like to look into switching to Okta or another service that allows for MFA.
- Getting more involved with Cloud Operations QA, who want to help us with better load and contract testing in our deployment pieline.
- Various improvements to the Rules:
- Supporting new business requirements like CPU/GPU filtering and multiple matching.
- Allowing for Rules to be treated as sets, to make it safer when adjusting intertwined Rules.
- Improvements to the UI to give better insight into the effects of a change to a Rule.
- Investigating some architectural changes such as upgrading to Python 3 or adding a service layer.
Here's to another great year of Balrog development!

(Photo credit: Donna Oberes)